这是 BoLi 这周二提出的问题,他问我 RFS 在现代内核上真的有用吗。
RPS 的核心思想是在 GRO 之后、进入协议栈之前做一次软件的 CPU 负载重分配,把本来在 CPU 0 上的 skb 扔给其他 CPU;RFS 更进一步,说既然都在重新分配 skb 给 CPU 了,那我们不如直接扔给收包进程所在的 CPU,这样符合菊部性原理,能够更好利用 CPU cache。
这咋一听好像合理,但仔细推敲可能会有很多问号,好工程师的直觉简直无敌啊,我怎么就没有这种直觉
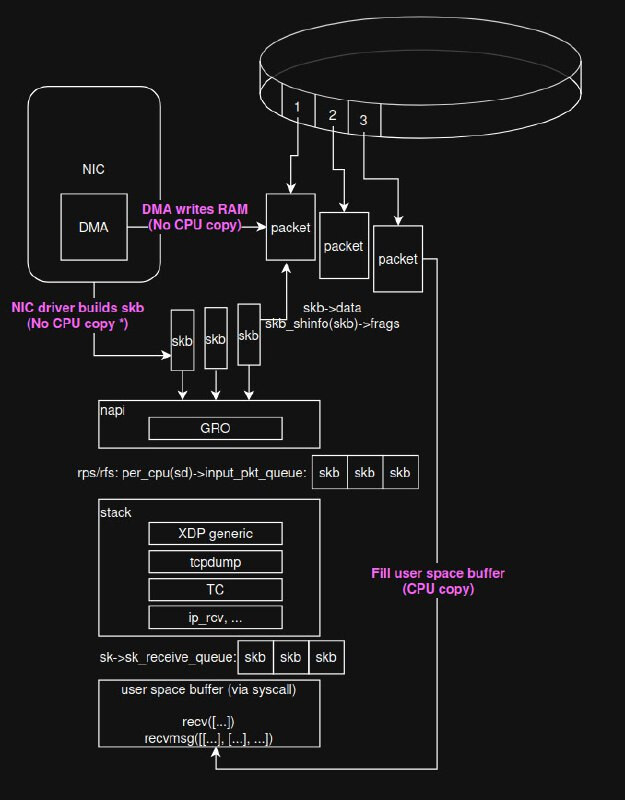
我画了一份 payload 数据视角的收包流程图,忽略了中断,特化为 tcp 收包,希望没有严重的事实性错误,如果有请斧正 ![]()
其中最重要的是三个加粗的 CPU copy,第一次是 DMA 拷贝,不消耗 CPU,所以不会产生 CPU cache;第二次是 build skb,在现代 NIC 上如 mlx5 都是零拷贝,直接让 skb->data 指向 packet va,所以也不会产生 CPU cache;第三次是用户态调用 syscall 才会触发真正的数据拷贝,由于之前 CPU 从没有拷贝过 payload,所以这一步无论在哪个 CPU 执行都无所谓,反正都没有 cache。
上面的第二步 build skb 需要特别说明,因为在 archurchiao 的权威指南里 (Linux 网络栈接收数据(RX):原理及内核实现(2022)) 把这一步称为“第二次数据拷贝”,然而我仔细看了一下 6.14 内核的 mlx5e_skb_from_cqe_linear → mlx5e_build_linear_skb → napi_build_skb → …,应该就是零拷贝的。 Archurchiao 是非常强悍的工程师,在荷兰人 Dylan Reimerink 的 docs.ebpf.io 公开之前,Auchurchiao 在 bpf、现代内核网络方面的博客甚至会让 google.ch (瑞士谷歌)收录他的中文博客。不过内核实在过于复杂,实在难以 100% 把握全部细节。
第二部 build skb 还需要另外说明,这一步是否零拷贝是网卡驱动的实现,比如在 qemu 虚拟机的 virtio interface 的实现里,就是用 GOOD_COPY_LEN (128) 来做分水岭:如果 > GOOD_COPY_LEN,零拷贝构造 skb;否则小包直接拷贝构造: Making sure you're not a bot!
让我们回到最初的问题,如果构造 skb 是零拷贝,那么 RFS 把 skb 重分配给接收进程所在的 CPU 还有用吗?我严重怀疑一点用都没有,反而由于重定向的软中断导致用户态进程被中断干扰、CPU cache 命中下降。 我尝试着做了一些实验,但都不太成功 高性能网络测试很复杂,我妄图通过本机 ubuntu desktop + qemu 搭建测试环境,但不管怎么绑核、绑 irq、隔离、驱逐干扰,测试结果都波动很大,构不成可信结论。看来还是要搞 homolab 呢如果有高性能网络专家有相关知识和经验,请交交我